Genetic Code
As DNA is a genetic material, it carries genetic information from cell to cell and from generation to generation.
- At this stage, an attempt will be made to determine in what manner the genetic information exists in the DNA molecule.
- Are they written in articulated or coded language on DNA molecules? If in the language of codes what is the nature of genetic code?
A DNA Molecule Is Composed Of Three Kinds Of Moieties:
- Phosphoric acid,
- Deoxyribose sugar, and
- Nitrogen bases.
The genetic information may be written in any one of the three moieties of DNA.
- However the poly-sugar-phosphate backbone is always the same, and it is, therefore, unlikely that these invitees of DNA molecules carry the genetic information.
- The nitrogen bases, however, vary from one segment of DNA to another, so the information might well depend on their sequences.
- The sequences of nitrogen bases of a given segment of a DNA molecule is identical to linear sequences of amino acids in a protein molecule.
- The proof of such a colinearity between DNA nitrogen base sequence and amino acid sequence in protein molecules was first obtained from an analysis of mutants of head protein of bacteriophage
- T4 (Sarabhai et al., 1964) and the A protein of tryptophan synthetase of Escherichia coli (Yanofski et al., 1964).
“What is degeneracy of the genetic code? A detailed notes guide”
- The collinearity of protein molecules and DNA polynucleotides has given the clue that the specific arrangement of four nitrogen bases (for example., A, T, C, and G ) in DNA polynucleotide chains, somehow, determines the sequence of amino acids in protein molecules.
- Therefore, these four DNA bases can be considered as four alphabets of DNA molecules.
- All the genetic information, therefore, should be written by these four alphabets of DNA.
- Now the question arises whether the genetic information is written in articulated language or coded language.
- If genetic information has occurred in an articulated language, the DNA molecule might require various alphabets, a complex system of grammar, and an ample amount of space on it.
- All of which might be practically impossible and troublesome too for the DNA.
- Therefore, it was safe to conclude for molecular biologists that genetic information existed in DNA molecules in the form of certain special language of code words which might utilize the four nitrogen bases of DNA for its symbols.
- Any coded message is commonly called a cryptogram.
Basis Of Cryptoanalysis
The basic problem of such a genetic code is to indicate how information written in a four-letter language (four nucleotides or nitrogen bases of DNA) can be translated into a twenty-letter language (twenty amino acids of proteins).
- The group of nucleotides that specifies one amino acid is a code word or codon. By the genetic code, one means the collection of base sequences (codons) that correspond to each amino acid and translation signals.
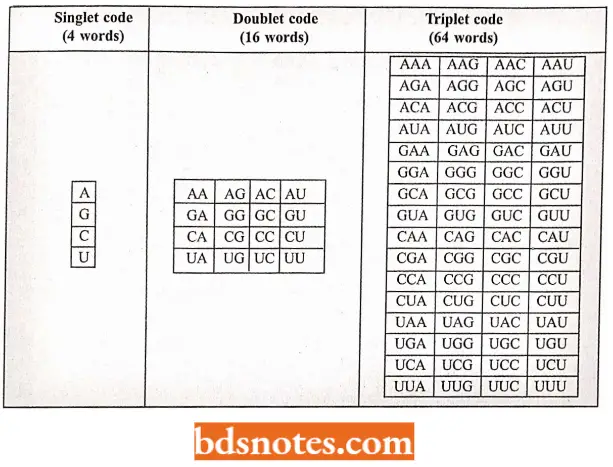
- We can consider here the classical but logical reasoning done by George Gamov (1954) about the possible size of a codon. The simplest possible code is a singlet code (a code of a single letter) in which one nucleotide amino acid could be specified.
- A doublet code (a code of two letters) is also inadequate because it can specify only sixteen (4 × 4) amino acids, whereas a triplet code (a code of three letters) could specify sixty-four (4×4×4) amino acids. Therefore, it is likely that there may be 64 triplet codes
206 I Molecular Biology for 20 amino acids. - The possible singlet, doublet, and triplet codes, which are customarily represented in terms of “mRNA language” (mRNA is a complementary molecule that copies the genetic information (cryptogram of DNA) during its transcription), have been illustrated.
Possible Singlet, Doublet, And Triplet Codes Of mRNA:
“Understanding degeneracy of the genetic code through FAQs: Q&A explained”
- The first experimental evidence in support of the concept of triplet code was provided by Crick and coworkers in 1961.
- During their experiment, when they added or deleted single or double base pairs in a particular region of DNA of T4 bacteriophages of E. coli, they found that such bacteriophages ceased to perform their normal functions.
- However, bacteriophages with the addition or deletion of three base pairs in DNA molecules performed normal functions.
- From this experiment, they concluded that a genetic code is in triplet form because the addition of one or two nucleotides has put the reading of the code out of order, while the addition of a third nucleotide resulted in a return to the proper reading of the message.
Codon Assignment (Cracking the Code or Deciphering the Code)
The genetic code has been cracked or deciphered by the following kinds of approaches :
Theoretical Approach: The physicist George Gamovv proposed the diamond code (1954) and the triangle code (1955) and suggested an exhaustive theoretical framework for the different aspects of the genetic code. Gamow suggested the following properties of the genetic code:
- A triplet codon corresponds to one amino acid of the polypeptide chain.
- Direct template translation by codon-amino acid pairing.
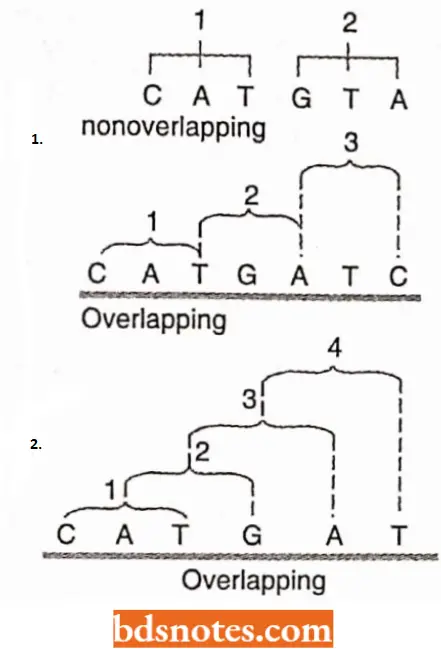
- Translation of the code in an overlapping manner.
- Degeneracy of the code, i.e., an amino acid being coded by more than one codon.
- Colinearity of nucleic acid and the primary protein synthesized.
- Universality’ of the code, i.e., the code is essentially the same for different organisms. Some of Gamow’s proposals have been contradicted by molecular biologists.
“Importance of studying degeneracy of the genetic code for biology students: Questions explained”
- For example, Brenner (1957) showed that the overlapping triplet code is an impossibility, and subsequent work has shown that the code is a non-overlapping one.
- Similarly, Gamow’s idea of a direct template relationship between nucleic acid and polypeptide chain was challenged when Crick proposed his adopter hypothesis.
- According to this hypothesis, adaptor molecules intervene between nucleic acid and amino acids during translation.
- It is now known that tRNA molecules act as adaptors between codons of mRNA and amino acids of the resulting polypeptide chain.
The In Vitro Codon Assignment: Discovery and use of polynucleotide phosphorylase enzyme. Marianne Grunberg-Manago and Severo Ochoa isolated an enzyme from the bacteria (e.g., Azobacter vinelandi or Micrococcus lysodeikticus) that catalyzes the breakdown of RNA in bacterial cells.
- This enzyme is called polynucleotide phosphorylase.
- Manago and Ochoa found that outside of the cell (in vitro), with high concentrations of ribonucleotides, the reaction could be driven in reverse and an RNA molecule could be made (see Burns and Bottino, 1989).
“Common challenges in understanding genetic code degeneracy effectively: FAQs provided”
- The incorporation of bases into the molecule is random and does not require a DNA template.
- Thus, in 1955 Manago and Ochoa made possible the artificial synthesis of polynucleotides ( = mRNA) containing only a single type of nucleotides (U, A, C, or G respectively) repeated many times.
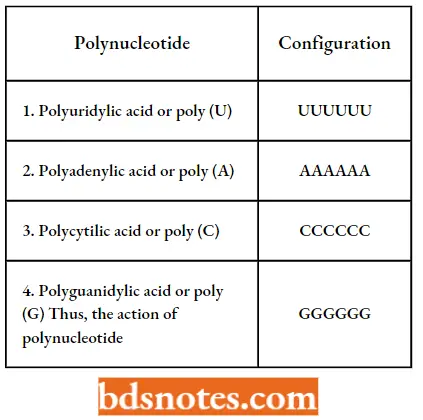
Thus, the action of polynucleotide phosphorylase can be represented in the following way:

RNA polymerase is used to transcribe mRNA from DNA in that:
- It does not require a template or primer ;
- The activated substrates are ribonucleoside diphosphates (e.g., UDP, ADP, CDP, and GDP ) and not triphosphates; and
- Orthophosphate (Pi) is produced instead of pyrophosphates (PPi).
The deciphering of the genetic code was made possible by the use of synthetic (or artificial) polynucleotides and trinucleotides.
- The different types of techniques used include the use of polymers containing a single type of nucleotide (called homopolymers ).
- The use of mixed polymers (copolymers) containing more than one type of nucleotide ( heteropolymers ) in random or defined sequences, and the use of trinucleotides (or “mini messengers”) in ribosome-binding or filter-binding.
Codon assignment with unknown sequence: Codon assignment by homopolymer.
- The first clue to codon assignment was provided by Marshall Nirenberg and Heinrich Matthaei (1961) when they used an in vitro system for the synthesis of a polypeptide using an artificially synthesized mRNA molecule containing only one type of nucleotide (i.e., homopolymer).
- Before performing the actual experiments, they tested the ability of a cell-free protein synthesizing system to incorporate radioactive amino acids into newly synthesized proteins.
- Their cell-free extracts of E.coli contained ribosomes, tRNAs, aminoacyl-tRNA synthetase enzymes, DNA, and mRNA.
- The DNA of this extract was eradicated with the help of the deoxyribonuclease enzyme, thus, the template that might synthesize new mRNA was destroyed.
- When twenty amino acids were added to this mixture along with ATP, GTP, K+, and MG2+ they were incorporated into proteins.
- This incorporation continued so long as mRNA was present in such a cell-free suspension.
- It also continued in the presence of synthetic polynucleotides (mRNAs) which could be made with the help of polynucleotide phosphorylase enzyme.
The first successful use of this technique was made by Nirenberg and Matthaei who synthesized a chain of uracil molecules (poly U) as their synthetic mRNA (homopolymer).
- Poly (U) seemed a good choice because there could be no ambiguity in a message consisting of only one base.
- Poly (U) was a good choice for other reasons: it binds well to ribosomes and, as it turned out, the product protein was insoluble and easy to isolate.
- When poly (U) was presented as the message to the cell-free system containing all the amino acids, one amino acid was exclusively selected from the mixture for incorporation into the polypeptide, called polyphenylalanine.
- This amino acid was phenylalanine and it could be concluded that some sequence of UUU coded for phenylalanine.
- Other homogeneous chains of nucleotides (Poly A, Poly C, and Poly G) were inactive for phenylalanine incorporation.
- The mRNA code word for phenylalanine was, therefore, shown to be UUU. Thus, the first code word to be deciphered was.
- This discovery was extended in the laboratories of Nirenberg and Ochoa. The experiment was repeated using synthetic poly (A) and poly (C) chains, which gave polylysine and polyproline respectively. Thus, AAA was identified as the code for lysine, and CCC as the code for proline.
- A poly (G) message was found non-functional in vitro, since it attains a secondary structure and, thus, could not attach the ribosomes. In this way, three of the 64 codons were easily accounted for.
“Why is early learning of genetic code degeneracy critical for molecular biology? Answered”
Codon assignment by heteropolymers (Copolymers with random sequences): Further exposition of the genetic code took place by using synthetic messenger RNAs containing two kinds of bases.
- This technique was used in the laboratories of Ochoa and Nirenberg and led to the deduction of the composition of codons for the 20 amino acids.
- The synthetic messengers contained the bases at random (called random copolymers).
- For example, in a random copolymer using U and A nucleotides eight triplets are possible, such as UUU, UUA, UAA, UAU, AAA, AAU, AUU, and AUA.
- Theoretically, eight amino acids could be coded by these eight codons. Actual experiments, however, yielded only six phenylalanine, leucine, tyrosine, lysine, asparagine, and isoleucine.
- By varying the relative compositions of U and A in the random copolymer and determining the percentage of the different amino acids in the proteins formed, it was possible to deduce the composition of the code for different amino acids.
Assignment of codons with known sequences: Use of trinucleotides or mini messengers in filter binding (Ribosome-binding technique).
- The ribosome technique of Nirenberg and Leder (1964) made use of the finding that aminoacyl-tRNA molecules specifically bind to the ribosome-mRNA complex.
- The binding does not require the presence of a long mRNA molecule; in fact, the association of a trinucleotide or mini messenger with the ribosome is sufficient to cause aminoacyl-tRNA binding.
- When a mixture of such small mRNA molecules-ribosomes and amino acid-tRNA complexes are incubated for a short time and then filtered through a nitrocellulose membrane, then the mRNA-ribosome-tRNA-amino acid complex is retained back and the rest of the mixture passes through the filter.
- By using a series of 20 different amino acid mixtures, each containing one radioactive amino acid at a time, it is possible to find out the amino acid corresponding to each triplet by analyzing the radioactivity absorbed by the membrane, for example., the triplet GCC and GUU retain only alanyl-tRNA and valyl-tRNA respectively.
- All 64 possible triplets have been synthesized and tested in this way. Forty-five of them have given clear-cut results.
- Later on, with the help of longer synthetic messages, it was possible to decipher 61 out of the possible 64 codons.
The In Vivo Codon Assignment: The cell-free protein synthetic systems, though have proved of great significance in the decipherment of the genetic code, but they could not tell us whether the genetic code so deciphered is used in the living systems of all organisms also.
- Three kinds of techniques are used by different molecular biologists to determine whether the same code is also used in vivo amino acid replacement studies (for example., tryptophan synthetase synthesis in E.coli (Yanofsky et al. 1963) and hemoglobin synthesis in humans), frameshift mutations (eg., investigations of Terzaghi et al.
- 1966, on lysozyme enzyme of T4 bacteriophages, and comparison of a DNA or mRNA polynucleotide cryptogram with its corresponding polypeptide clear text (for example., comparison of the amino acid sequence of the R17 bacteriophage coat protein with the nucleotide sequence of the R17 mRNA in the region of the molecule that dictates coat-protein synthesis by S. Cory et al., 1970).
- Thus, in vitro and in vivo studies, so far described, gave the way to formulate a code table for twenty amino acids.
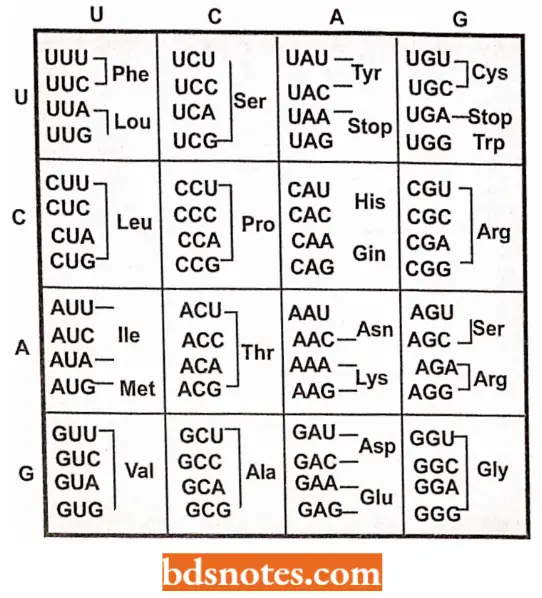
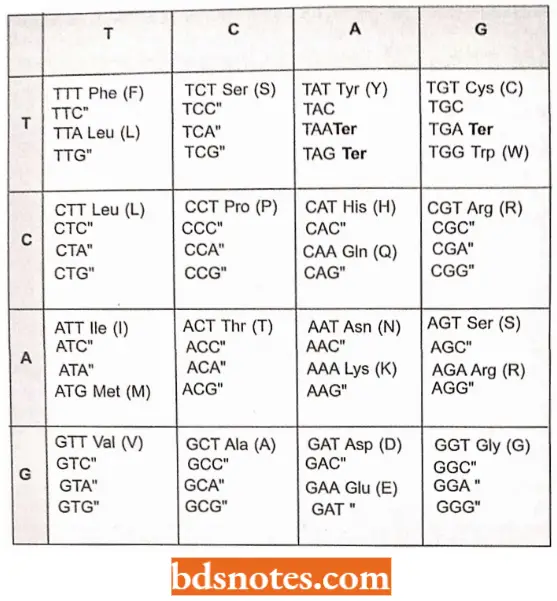
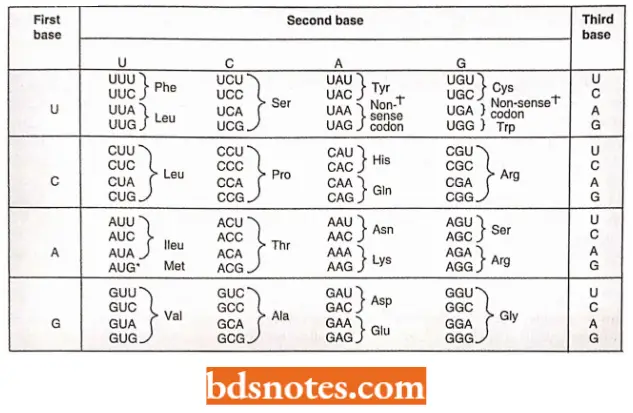
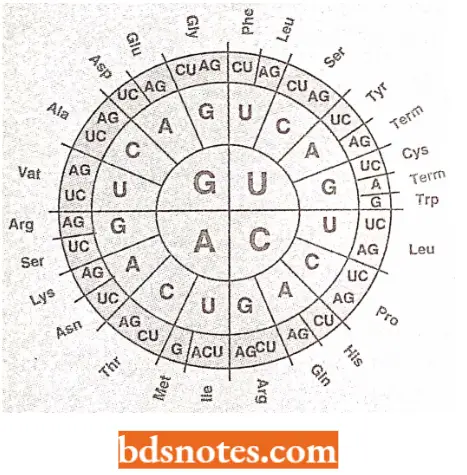
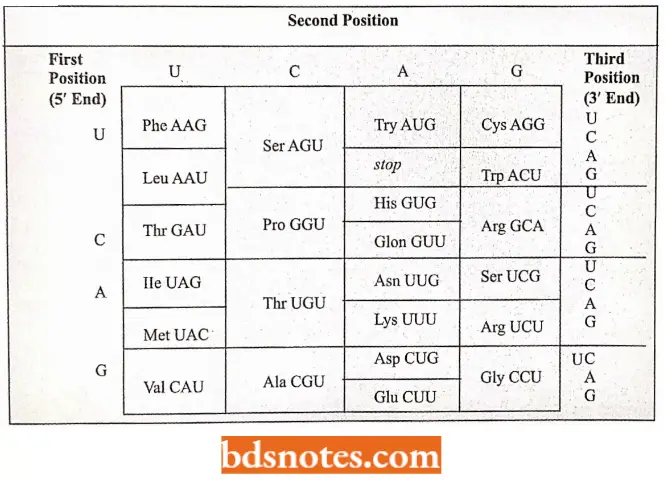
The Genetic Dictionary. The Trinucleotide Codons Are Written In The 5′ → 3′ Direction:
“Factors influencing success with genetic code knowledge: Q&A”
*AUG—Met or chain initiation codon: UAA, UAG, UGA—Stop Codon.
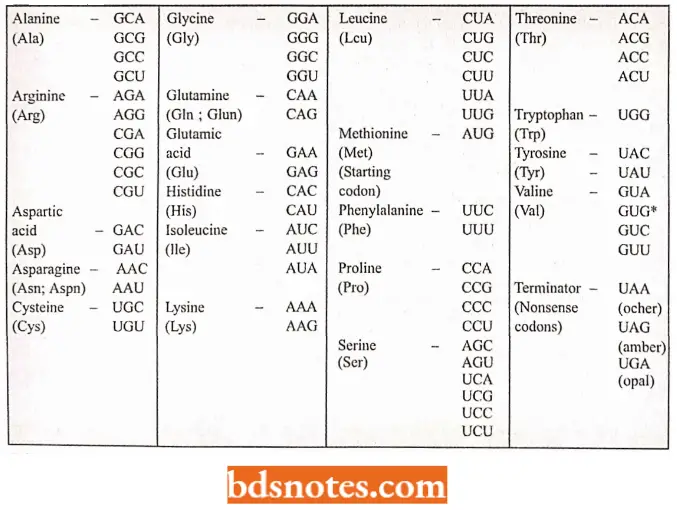
Amino Acids And Their Messenger Rna Codons:
Characteristics Of Genetic Code
The genetic code has the following general properties:
- The code is a triplet codon. The nucleotides of mRNA are arranged as a linear sequence of codons, each codon consisting of three successive nitrogenous bases, i.e., the code is a triplet codon.
- The concept of triplet codon has been supported by two types of point mutations: frameshift mutations and base substitution.
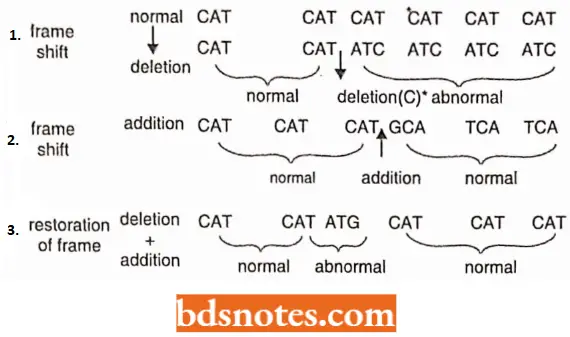
Frameshift mutations: The genetic message once initiated at a fixed point is read in a definite frame in a series of three-letter B-frame words.
- The framework would be disturbed as soon as there is a deletion or addition of one or more bases. When such frameshift mutations were intercrossed, then in certain combinations they produced wild-type normal genes.
- It was concluded that one of them was a deletion and the other an addition so that the disturbed order of the frame due to mutation would be restored by the other.
“Steps to explain degeneracy of the genetic code: Codon vs amino acid: Q&A guide”
Base substitution: If in a mRNA molecule at a particular point, one base pair is replaced by another without any deletion or addition, the meaning of one codon containing such an altered base, will be changed.
- In consequence, in place of a particular amino acid at a particular position in a polypeptide, another amino acid will be incorporated.
- For example, due to substitution mutation, in the gene for tryptophan synthetase enzyme in E.coli, the GGA codon for glycine becomes a missencc codon AGA which codes for arginine. Missence codon is a codon that undergoes an alteration to specify another amino acid.
- A more direct evidence for a triplet code came from the finding that a piece of mRNA containing 90 nucleotides, corresponded to a polypeptide chain of 30 amino acids of a growing haemoglobin molecule. Similarly, 1200 nucleotides of the “satellite” tobacco necrosis virus direct the synthesis of coat protein molecules which have 372 amino acids.
The code is non-overlapping: In translating mRNA molecules the codons do not overlap but are “read” sequentially. Thus, a non-overlapping code means that a base in a mRNA is not used for different codons.
- It has been shown that an overlapping code can mean coding for four amino acids from six bases. However, in actual practice six bases code for not more than two amino acids.
- For example, in case of an overlapping code, a single change (substitution type) in the die base sequence will be reflected in substitutions of more than one amino acid in the corresponding protein.
- Many examples have accumulated since 1956 in which a single base substitution results in a single amino acid change in insulin, tryptophan synthetase, TMV coat protein, alkaline phosphatase, hemoglobin, etc.

Recently, however, it has been shown that in the bacteriophage Φ × 174, there is a possibility of overlapping of genes and codons (Barrel and coworkers, 1976; Sanger, et al, 1977).
The code is commaless: The genetic code is commaless, which means that no codon is reserved for punctuation.
- It means that after one amino acid is coded, the second amino acid will be automatically coded by the next three letters and that no letters are wasted as punctuation marks.
“Role of synonymous codons in genetic code degeneracy: Questions answered”
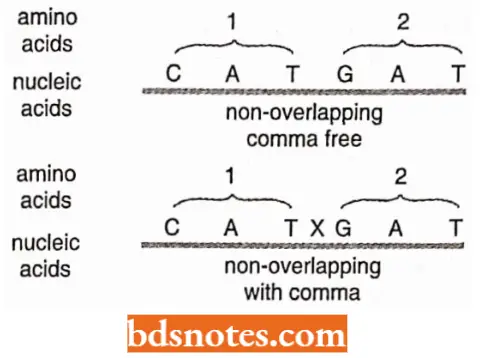
The code is non-ambiguous: Non-ambiguous code means that a particular codon will always code for the same amino acid.
- In case of ambiguous code, the same codon could have different meanings or in other words, the same codon could code two or more than two amino acids.
- Generally, as a rule, the same codon shall never code for two different amino acids.
- However, there are some reported exceptions to this rule: the codons AUG and GUG both may code for methionine as an initiating or starting codon, although GUG is meant for valine.
- Likewise, the GGA codon codes for two amino acids glycine and glutamic acid.
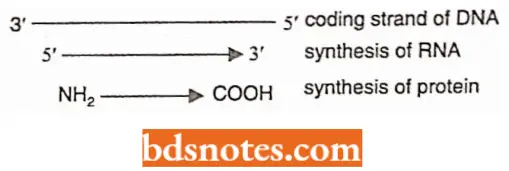
The code has polarity: The code is always read in a fixed direction, i.e., in the 5′ → 3′ direction.
- In other words, the codon has a polarity.
- It is apparent that if the code is read in opposite directions, it would specify two different proteins since the codon would have reversed base sequence:

The code is degenerate: More than one codon may specify the same amino acid; this is called the degeneracy of the code.
- For example, except for tryptophan and methionine, which have a single codon each, all other 18 amino acids have more than one codon.
- Thus, nine amino acids, namely phenylalanine, tyrosine, histidine, glutamine, asparagine, lysine, aspartic acid, glutamic acid, and cysteine, have two codons each. Isoleucine has three codons.
- Five amino acids, namely valine, proline, threonine, alanine, and glycine, have four codons each. Three amino acids, namely leucine, arginine, and serine, have six codons each.
- The code degeneracy is basically of two types: partial and complete.
- Partial degeneracy occurs when the first two nucleotides are identical but the third nucleotide of the degenerate codons differs, e.g., CUU and CUC code for leucine.
- Complete degeneracy occurs when any of the four bases can take third position and still code for the same amino acid (for example., UCU. UCC. UCA, and UCG code for serine).
- Degeneracy of genetic code has certain biological advantages.
- For example, it permits essentially the same complement of enzymes and other proteins to be specified by microorganisms varying widely in their DNA base composition.
- Degeneracy also provides a mechanism for minimizing mutational lethality.
Some codes act as start codons: In most organisms, the AUG codon is the start or initiation codon, i.e., the polypeptide chain starts either with methionine (eukaryotes) or N-formylmethionine.
“Early warning signs of gaps in understanding genetic code basics: Common questions”
Genetic code is degenerate, not ambiguous: After the start and stop codons, the remaining 60 codons are far more than enough to code for the other 19 amino acids-and indeed there are repeats.
- Thus we say that the genetic code is degenerate, that is, an amino acid may be represented by more than one codon.
- The degeneracy is not evenly divided among the amino acids. For example, methionine and tryptophan are represented by only one codon each, whereas leucine is represented by six different codons.
- The term “degeneracy” should not be confused with “ambiguity”.
- To say that the code o was ambiguous would mean that a single codon could specify either of two (or more) different amino acids: there would be doubt about whether to put in, say leucine or something else. The genetic code is not ambiguous.
- Degeneracy in the code means that there is more than one clear way to say “Put leucine here”.
- In other words, a given amino acid may be encoded by more than one codon, but a codon can code for only one amino acid. But just as people in different places prefer different ways of saying the same thing —“Goodbye”! “See you” l “Ciao”! and “So long” have the same meaning — different organisms prefer one or other of the degenerate codons (Ciao means informal hello or good be).
- These preferences are important in genetic engineering. (prokaryotes), methionyl or N-formyl methionyl-tRNA specifically binds to the initiation site of mRNA containing the AUG initiation codon.
- In rare cases, GUG also serves as the initiation codon, for example., bacterial protein synthesis.
- Normally GUG codes for valine, but when a normal AUG codon is lost by deletion, only then GUG is used as an initiation codon.
“Asymptomatic vs symptomatic effects of ignoring genetic code degeneracy: Q&A”
Some codes act as stop codons: Three codons UAG, UAA, and UGA are the chain stop or termination codons. They do not code for any amino acids.
- These codons are not read by any tRNA molecules (via their anticodons) but are read by specific proteins, called release factors (e.g., RF-1, RF-2, RF-3 in prokaryotes and RF in eukaryotes).
- These codons are also called nonsense codons since they do not specify any amino acid. The UAG was the first termination codon to be discovered by Sidney Brenner (1965).
- It was named amber after a graduate student named Bernstein (= the German word for ‘amber’ and amber means brownish yellow) who helped in the discovery of a class of mutations.
- Apparently, to give uniformity the other two termination codons were also named after colors such as ochre for UAA and opal or number for UGA. (Ochre means yellow red or pale yellow; opal means milky white and umber means brown).
- The existence of more than one stop codon might be a safety measure, in case the first codon fails to function.
The Code Is Universal: The same genetic code is found valid for all organisms ranging from bacteria to man.
Such universality of the code was demonstrated by Marshall, Caskey, and Nirenberg (1967) who found that E.coli (bacterium), Xenopus Iaevis (amphibian), and guinea pig (mammal) amino acyl-tRNA use almost the same code.
Nirenberg has also stated that the genetic code may have developed 3 billion years ago with the first bacteria, and it has changed very little throughout the evolution of living organisms.
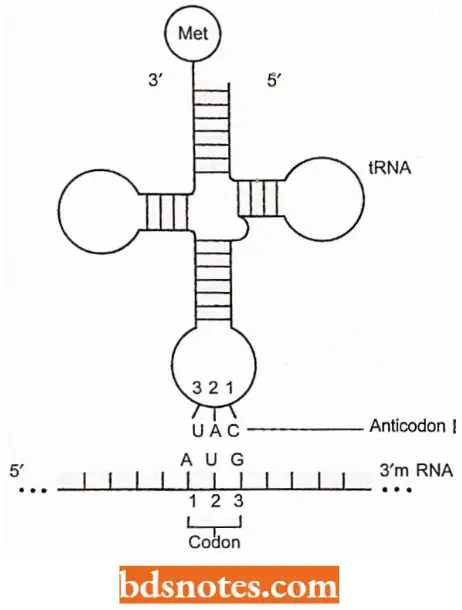
Codon and Anticodon The codon words of DNA would be complementary to the mRNA code words (i.e., DNA codes run in 3′ → 5′ direction and mRNA code words run in 5′ → 3′ direction) and so thereby the three bases forming the anticodon of tRNA (i.e., bases of anticodons run in 3′ → 5′ direction).
- Three bases of anticodon pair with the mRNA on the ribosomes at the time of aligning the amino acids during protein synthesis (translation of mRNA into proteins which proceeds in N2 — COOH direction).
- For example, one of two mRNA and DNA code words for the amino acid phenylalanine is UUC and AAG respectively, and the corresponding anticodon of tRNA is CAA.
- This indicates that codon and anticodon pairing is antiparallel. In this case, C pairs with G, and U pairs with A.
Wobble Hypothesis
The genetic code is degenerate, meaning that a given amino acid may have more than one codon. As you can see eight of the sixteen boxes contain just one amino acid per box (e.g., serine, leucine, proline, arginine, threonine, valine, alanine, and glycine). (A box is determined by the first and second positions, e.g., the UUX box in which X is any of the four bases).
- Therefore, for these eight amino acids, the codon need only be read in the first two positions because the same amino acid will be represented regardless of the third base of the codon.
- These eight groups of codons are termed unmixed families of codons. An unmixed family is the four codons beginning with the same two bases that specify a single amino acid.
- For example the codon family GUX codes for valine.
Mixed Families of codons code for two amino acids or stop signals and one or two amino acids.
- Six of the mixed-family boxes are split in half so that the codons are differentiated by the presence of a purine or a pyrimidine in the third base.
- For example, CAU and CAC both code for histidine: in both, the third base, U (uracil) or C (cytosine) is a pyrimidine. Only two of the families of codons are split differently.
- The lesser importance of the third position is the genetic code is linked with two facts about transfer RNAs.
- First, although there would seem to be a need for sixty-two transfer RNAs— since there are sixty-one (i.e., one codon specifying amino acids and an additional codon for initiation) there are only about fifty different transfer RNAs in an E.coli cell.
“Can targeted interventions improve outcomes using genetic code knowledge? FAQs provided”
- Second, a rare base such as inosine can appear in the anticodon, usually in the position that is complementary to the third position of the codon.
- These two facts researchers believe that some kind of conservation of transfer RNAs is occurring and that rare bases may be involved.
- At this stage, one point should be very clear both messenger RNA and transfer RNA bases are usually numbered from the 5′ side. Thus, the number one base of the codon is complementary to the number three base of the anticodon.
- Thus, the codon base of lesser importance is the number-three base, whereas its complement in the anticodon is the number-one base.
- Since the first position of the anticodon (5′) is not as constrained as the other two positions, a given base at that position may be able to pair with any of several bases in the third position of the codon.
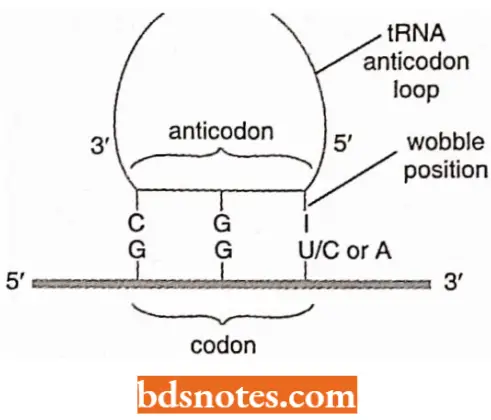
- Crick (1966) characterized this ability as wobble (wobble means to sway or move unsteadily).
- The possible pairings that would produce a transfer RNA system compatible with the known code.
- For example, if an isoleucine transfer RNA has the anticodons 3′-UAI-5′, it is compatible with the three codons for that amino acid: 5′- AUU’ -3′, 5′- AUC-3′ and 5′-AUA-3′.
- That is inosine is in the first (5′) position of the anticodon and can recognize U, C, or A in the third (3′) position of the codon, and thus one transfer RNA complements all three codons for isoleucine.
Pairing Combinations At The Third Codon Position:

“Differential applications of degenerate vs non-degenerate codons: Questions answered”
Deviations From The Universality Of Genetic Code
Molecular biologists concluded by 1979 that the genetic code was universal. That is the code dictionary was the same for E. coli, human beings, and oak trees, as well as other species investigated up to that time.
- The universality of the genetic code was demonstrated, for example, by taking the ribosomes and messenger RNA from rabbit reticulocytes and mixing them with the aminoacyl-tRNA and other translational components of E. coli. Rabbit hemoglobin was synthesized.
- Around 1980, however, researchers noted divergence when sequencing mitochondrial genes for structural proteins.
- It was discovered that there were two kinds of deviations from universality in the way mitochondrial transfer RNAs read the code.
- First, fewer transfer RNAs were needed to read the genetic code, second, there were several cases in which the mitochondrial and cellular systems interpreted a codon differently.
According to Crick’s wobble rules, thirty-two transfer RNAs (including one for initiation) can complement all sixty-one non-terminating codons.
- For example, unmixed families of codons require two transfer RNAs, and mixed families of codons require one, two, or three transfer RNAs, depending on the family.
- The yeast mitochondrial coding system needs only twenty-four transfer RNAs.
- The reduction in numbers is attained primarily by having only one transfer RNA recognize each unmixed family.
The Genetic Code Dictionary Of Yeast Mitochondria; Anticodons (3′ → 5′) Are Given Within Boxes (Source):
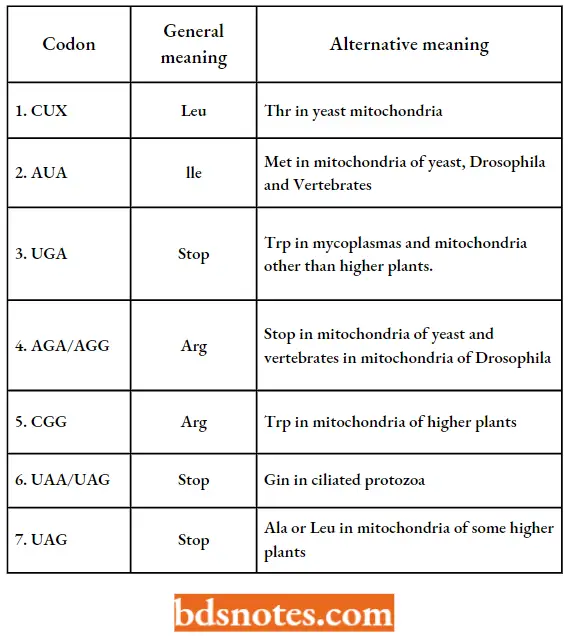
- Because mitochondrial transfer RNAs for unmixed families of codons have a U in the first (i.e., wobble) position of the anticodon, apparently, given the structure of the mitochondrial transfer RNAs, the U can pair with U, C, A, or G.
- Most probably, evolutionary pressure has minimized the number of transfer RNA genes in the DNA of the mitochondrion, in keeping with its small size. Reduction from thirty-two to twenty- four is a 25% savings.
- Recent evidence suggests that mammalian mitochondria may need only twenty-two transfer RNAs.
- It has also been found that yeast mitochondria read the CUX family (i.e., CUU, CUC, CUA, CUG) as threonine rather than as leucine and the terminator UCA (opal) as tryptophan rather than as tennination.
- However, there have been found differences among mitochondria of different groups of organisms reading the CUX family.
- Human and Neurosporci mitochondria appear to read the CUX codons as leucine just as cellular systems do. Of the groups so far analyzed, only yeast reads the CUX family as threonine.
- Similarly, human and Drosophila mitochondria read AGA and AGG as stop signals rather than as arginine.
Common And Alternative Meanings Of Codons (Source):
“Steps to incorporate AI into analyzing genetic code degeneracy: Questions and answers”
- The ciliated protozoan Paramecium species read the UAA and UAG stop codons as glutamine within the cell. In addition, a prokaryote (Mycoplasma capricolum) reads UGA codon as tryptophan.
- We do not yet know how general this finding is: scientists have analyzed the genetic code of every new species.
- We can thus conclude that the genetic code seems to have universal tendencies among prokaryotes, eukaryotes, and viruses.
- Mitochondria, however, read the code slightly differently: different, wobble rules apply, and mitochondria and cells read at least one terminator and one unmixed family of codons differently.
- Also, the mitochondrial deviations are not universal among all types of mitochondria.
Further work, involving the sequencing of more mitochondrial DNAs, should explain the pattern of deviations among the mitochondria of diverse species.
- Further, it has also become clear that not every organism reads all codons in the same way. For example, ciliated protozoa and mycoplasma read some stop signals as coding for amino acids. Likewise, nuclear variants are known in the following codons: CUG, AUA, UAA, UAG, UGA, CGG, and AGA.
- Mitochondrial variants are known in CUX, AUA, UAA, UAG, AAA, UGA, CGX, AGA, and AGG.
- Site-specific variation. In this type of variation in codon reading, the interpretation of a codon depends on its specific location.
- For example, codons GUG and, rarely, UUG can serve as prokaryotic initiation codons. This means that they are recognized by tRNAmMet. However, they are not recognized by tRNAfMet. (i.e., GUG and UUG are not misread internally in messenger RNAs).
- In some cases, two of the termination codons (UGA and UAG, but not UAA) are misinterpreted as codons for amino acids. That is, the termination will not occur at the normal place, resulting in a longer-than-usual protein.
- In some cases, these “read-through” proteins are vital — the organism depends on their existence. For example, in phage θβ, the coat-protein gene is read through about 2% of the time.
Without this small number of read-through proteins, the phage coat (capsid) cannot be constructed properly.
- Selenocssteine codon. Site-specific variation also involves the amino acid selenocysteine (i.e., cysteine with a selenium atom replacing the sulfur).
- Although many proteins have unusual amino acids, almost all are due to post-translational modifications of normal amino acids.
- However, the amino acid selenocysteine is inserted directly into some proteins, such as formate dehydrogenase in E. coli, which has selenium in its active site.
- Selenocysteine is inserted into the protein by a new transfer RNA that recognizes the termination codon, UGA if that codon is involved in a particular stem-loop secondary structure in the messenger RNA.
- The selenocysteine transfer RNA is originally charged with a serine that is then modified to a selenocysteine.
- In addition to the stem-loop structure 3′ (downstream) from the amber codon (UAG), a selenocysteine elongation factor (SELB) is also needed at the ribosome. This same mechanism may occur in eukaryotes, but not all of the components have yet been recognized.

“Role of digital tools in improving precision with genetic code tracking: FAQs explained”
Evolution Of Genetic Code
Certain modern theories have suggested that the genetic code has a wobble in it because it originally arose from a code in which only the first two bases were needed for the small number of amino acids in use several billion years ago.
- As new amino acids with useful properties became available, they were incorporated into proteins by a code modified by the third base, albeit with less specificity.
- This view has been supported by the fact that codons starting with the same nucleotide come from the same biosynthetic pathway.
- This indicates that in early evolution, as biosynthetic pathways were extended to new amino acids, the newcomers were incorporated by use of the second and the third bases of the code.
- Let us see whether there is a relationship between the codons and the amino acids they code for, or is the code just one of many random/chance possibilities.
- That is, whether the genetic code is highly evolved or just a “frozen accident”.
- Recent computer simulations of random codes indicate that the current genetic code is far outside the range of random in its ability to protect the organism from mutation.
This suggests that the genetic code is not a frozen accident, but rather is highly evolved. Numerous examples in the current code support this view.
- For example, in the unmixed family 5′-CUX -3′, any mutation in the third position produces another codon for the same amino acid.
- Wobble in the third position and codon arrangement ensures that less than half of the mutations in the third codon position result in the specification of a different amino acid.
- Some patterns also have been observed in the genetic code. For example, the mutation of one codon to another results in an amino acid of similar properties. A high probability exists that such a mutation will produce a functional protein.
- All the codons with U as the middle base, for example, are for hydrophobic amino acids (e.g., phenylalanine, leucine, isoleucine, methionine, and valine). Mutation in the first or third positions for any of these codons still codes hydrophobic amino acids.
- Both of the two negatively charged amino acids, aspartic acid, and glutamic acid, have codons that start with GA.
- All of the aromatic amino acids —phenylalanine, tyrosine, and tryptophan- have codons that begin with uracil. Such patterns minimize the negative effects of mutation (see Tamarin, 2002).
“How do advancements in technology enhance genetic code research? Q&A guide”
Genetic Code Questions And Answers
Question 1. The size of the hemoglobin gene in humans is estimated to consist of approximately 450 nucleotide pairs. The protein product of the gene is estimated to consist of about 150 amino acid residues. Calculate how many nucleotides are present in a genetic codon for each amino acid.
Answer:
Approximately 3 nucleotides code for each amino acid.
Question 2. How many triplet codons can be made from the four ribonucleotides A, U, G, and C containing
- No uracils;
- One or more uracils?
Answer:
- Since uracil represents 1 among 4 nucleotides; the probability that uracil will be the first letter of the codon is 1/4 and the probability that U will not be the first letter is 3/4. The same reasoning holds for the second and third letters of the codon. The probability that none of the three letters of the codon are uracils is (3/4)3 = 27/64.
- The number of codons containing at least one uracil is 1 – 27/64 = 37/64.
Question 3. Assume a series of different one-base changes in the codon GGA, which produces the following several new codons:
- UGA;
- GAA;
- GGC,
- CGA. Which of these represent
- Degeneracy, which missense, and which nonsense?
Answer:
- Nonsense; UGA is a stop signal and does not translate.
- Missense; GGA codes for glycine, GAA for glutamic acid.
- Degeneracy; both GGA and GGC code for glycine.
- Missense; GGA codes for glycine, CGA for arginine.
Question 4. If single-base changes occur in DNA (and, therefore, in mRNA), which amino acid, tryptophan or arginine, is most likely to be replaced by another in protein synthesis?
Answer: Tryptophan, which has only one codon. Arginine has six codons.
“Early warning signs of outdated methods in genetic code studies: Common questions”
Question 5. How was the genetic code first decoded? What refinements have since been incorporated into the technique?
Answer:
- Synthetic RNA molecules (polycytidylic acid molecules) containing only the base uracil were prepared when these synthetic molecules were used to activate in vitro protein synthesis systems, and small polypeptides containing only the amino acid phenylalanine (polyphenyl alanine molecules) were synthesized.
- Codons composed only of uracil were therefore shown to specify phenylalanine. Similar experiments were carried out using synthetic RNA molecules with different base compositions,
- Better in vitro systems activated with synthetic RNA molecules with known repeated base sequences were developed ultimately, in vitro systems in which specific aminoacyl-1 RNAs were shown to bind to ribosomes activated with specific mini-mRNAs, which were trinucleotides of known base sequence, were developed and used in codon identification.
Question 6. In what sense and to what extent is the genetic code
- Degenerate and
- Universal?
Answer:
- The genetic code is degenerated in that all but 2 of the 20 amino acids are specified by two or more codons. Some amino acids are specified by six different codons. The degeneracy occurs largely at the third or 3′ base of the codons.
- “Partial degeneracy “* occurs where the third base of the codon may be either of the two purines or either of the two pyrimidines and the codon still specifies the same amino acid. “Complete degeneracy” occurs where the third base of the codon may be any one of the four bases and the codon still specifies the same amino acid,
- The code appears to be almost completely universal.
- Known exceptions to universality include strains carrying suppressor mutations that alter the reading of certain codons (with low efficiencies in most cases) and the use of UGA as a tryptophan codon in yeast and human mitochondria.
Question 7. What evidence supports the hypothesis of colinearity between the nucleotide sequence in a gene and the amino acid sequence in a polypeptide?
Answer:
Colinearity received strong support from studies that showed a direct correlation between the linear sequence of mutational sites in a gene (established by genetic mapping experiments) and the linear sequence of mutational defects (amino acid substitutions or chain terminations) in the polypeptide gene product (established by purification and amino acid sequencing, etc., of mutant polypeptides).
Question 8. Why is colinearity between codons and polypeptides significant?
Answer:
Colinearity is an important prediction of our present concepts of noncoding sequences (“introns” or “intervening sequences”) within eukaryotic genes does not violate the concept of colinearity; their presence simply means that the colinear structures frequently contain interruptions.
Question 9. A. Garen (1968) extensively studied a particular nonsense (Chain-termination) mutation in the alkaline phosphatase gene of E. coli. This mutation resulted in the termination of the alkaline phosphatase polypeptide chain at a position where the amino acid tryptophan occurred in the wild-type polypeptide. Garen-induced revertants (in this case, mutations altering the same codon) of this mutant with chemical mutagens that induced single base-pair substitutions and sequenced the mutant polypeptides. Seven different types of revertants were found, each with a different amino acid at the tryptophan position of the wild-type polypeptide (termination position of the mutant polypeptide fragment). The amino acids present at this position in the various revertants included tryptophan, serine, tyrosine, leucine, glutamic acid, glutamine, and lysine. Was the nonsense mutation studied by Garen an amber (UAG), an ochre (UAA), or an opal (UGA) nonsense mutation? Explain the basis of your deduction.
Answer:
Amber (UAG). This is the only nonsense codon that is related to tryptophan, serine, tyrosine, leucine, glutamic acid, glutamine, and lysine codons by a single base pair substitution in each case.
“Asymptomatic vs symptomatic effects of ignoring new trends in genetic code degeneracy: Answered”
Genetic Code Multiple Choice Questions And Answers
Question 1. Genetic code is a sequence of nitrogenous bases on
- mRNA
- tRNA
- rRNA
- DNA
Answer: 1. mRNA
Question 2. The terminator codons are
- UAA, UAG, UGA
- AUG, UAG, UGA
- UAC, AUG, UAG
- AUG, ACG, GAG
Answer: 1. UAA, UAG, UGA
Question 3. Who discovered the entire genetic code?
- Nirenberg
- Ochoa
- Khorana
- Crick
Answer: 1. Nirenberg
Question 4. A codon consists of how many nitrogen bases in it
- 1
- 2
- 3
- 4
Answer: 3. 3
Question 5. The arrangement of three bases in DNA represents
- Protein
- Amino acid
- Plasmid
- Nucleic acid
Answer: 2. Amino acid
Question 6. Degeneration of a genetic code is attributed to the
- The first member of the codon
- The second member of the codon
- Entire codon
- The third member of the codon
Answer: 4. Third member of codon
Question 7. In the genetic code dictionary, how many codons are used to code for all the 20 essential amino acids?
- 20
- 64
- 61
- 60
Answer: 3. 61
“Differential applications of traditional vs cutting-edge genetic code techniques: Questions answered”
Question 8. What would happen if, in a gene encoding a polypeptide of 50 amino acids, the 25th codon (UAU) is mutated to UAA?
- A polypeptide of 24 amino acids will be formed
- Two polypeptides of 24 and 25 amino acids will be formed
- A polypeptide of 49 amino acids will be formed
- A polypeptide of 25 amino acids will be formed
Answer: 3. A polypeptide of 49 amino acids will be formed
Question 9. Which of the chemical characteristics is not common to all living beings?
- Ribosomes are sites of protein synthesis
- Types of protein present in the body
- Energy is stored by high phosphate bonds,
- Similar triplet codes for amino acid
Answer: 4. Similar triplet codes for amino acid
Leave a Reply