Research Tool And Methods
Question 1. Research tool
Answer:
Research tool Definition
- A research tool may be defined as Anything that becomes a means of collecting information for your study is called a research tool or a research instrument. For example, observation forms, interview schedules, questionnaires, and interview guides are all classified as research tools.
- Measurements are the process of assigning numbers to variables. Measurements, as used in research, imply the qualification of information which is the assigning of some type of numbers to the data.
“Understanding research methods through FAQs: Q&A explained”
Read And Learn More: BSc Nursing 3rd Year Nursing Research And Statistics Previous year Question And Answers
Meaning Of Tools And Methods:
- There are many alternatives to choose from when selecting a data-collection method. These methods include questionnaires, interviews, physiological measures, attitude scales, psychological tests, and observational measures.
Question 2. Enumerate the principles for research tool creation.
Answer:
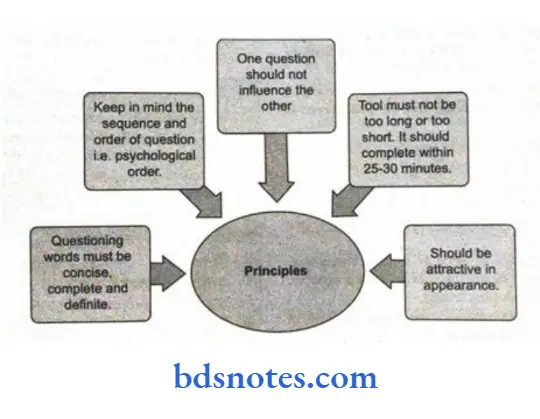
“Importance of studying research tools for BSc Nursing students: Questions explained”
Question 3. Define the reliability of the measuring Instrument.
Answer:
Measuring Instrument Definition:
- According to Chris Jordan, Reliability is the consistency of a set of measurements or measuring instruments often used to describe a test.
- According to Houghton, Reliability is an attribute of any system that consistently produces the same results, preferably meeting or exceeding its specifications.
- According to Livingstone, reliability is the ability of an item to perform a required function under stated conditions for a specified period of time.
Question 4. What are the factors affecting the reliability?
Answer:
1. Administrative factors:
- Poor or unclear directions given during administration or inaccurate scoring can affect reliability.
- For example: it says you were told that your scores on being social determined your promotion.
2. Number of items on the instrument:
- The larger the number of items, the greater the chance of high reliability. For example, it makes sense when you ponder that 20 questions on your leadership style are more likely to get a consistent result than four questions.
“Common challenges in understanding research methods effectively: FAQs provided”
3. The instrument taker:
- The response portrayed by the individual respondent will vary with considerable stress and much interference is faced by him during the test.
- For example, if you took an instrument in August when you had a terrible flu and then in December when you were feeling quite good we might see a difference in your response consistency.
- If you were under considerable stress of some sort or if you were interpreted, while answering the instrument questions, you might give different responses.
4. Heterogeneity of the:
- The greater the heterogeneity (differences in the kind of questions of difficulty of the questions) of the times, the greater the chance of high-reliability correlation coefficients.
- For example: if you throw a variety of questions, it is difficult to give an answer and also from various areas. Length of time between test and retest frame
5. Heterogeneity of the group members:
- The greater the heterogeneity of the group members in the preferences, skills, or behaviors being tested, the greater the chance for high-reliability correlation coefficients.
- For example, if the participants are from various professions the views will be different from one another.
6. Length of time between test and reset.
- The shorter the time, the greater the chance for high-reliability correlation coefficients. As we have experienced, we tend to adjust our views a little from time to time.
- Therefore, the time interval between experience intervals.
- Experience happens and it influences how we see things.
- Because internal consistency has no time-lapse, one can expect it to have the highest reliability correlation coefficient.
- For example, when less time is given between the test and retest regarding a particular topic the reliability will be High.
“Why is early learning of research tools critical for evidence-based practice? Answered”
Outside factors that affect reliability
- Fatigue, illness, emotions, motivational level, attitudes, and values, all affect reliability.
- Motivation is probably a more important factor, especially the motivation to study before taking the test.
- A student’s personality characteristics may affect his or her test scores. Sociable persons who enjoy communicating, and who are able to express themselves fluently will also often score higher than persons who lack such characteristics.
- Students‘ past experience with tests will influence their performance on subsequent tests.
- The quality of students’ past experiences with tests, if they have often achieved success.
- Students’ memory, fluency, and the like also enter into the reliability of a test. The higher these factors, the more reliable the test.
- Lapses of inattention, boredom, distractions, poor ventilation, and the like may serve to reduce a test’s reliability to some extent.
- In most cases, a teacher can increase reliability simply by ensuring that all students clearly understand test directions, are marking answer sheets correctly, and are not interrupted during the testing process.
- Elimination of distractions and maximization of students‘ comfort through good lighting, ventilation, and heating can also contribute to higher reliability.
“Steps to explain types of research tools: Questionnaires vs interviews: Q&A guide”
Question 5. Types of reliability
Answer:
Test-retest reliability or stability:
- It refers to the degree to which research participants’ responses change over time.
- The test-retest method is used to test the stability of the tool. In this method, an instrument is given to the same individuals on two occasions within a relatively short duration of time
- A correlation coefficient is calculated to determine how closely the participant’s responses on the second occasion matched their responses on the first occasion.
Half-split reliability or internal consistency:
- It is a measure of reliability that is frequently used with scales designed to assess psychosocial characteristics.
- Instruments can be assessed for internal consistency using the half-split-half technique (i.e. answers to one-half of the items are compared with answers to the other half of the items) or by calculating the alpha coefficient or using the Kuder-Richardson formula.
- In the case alpha coefficient and the Kuder-Richarcison formula, a coefficient that ranges from 0 to 1.00 usually results.
Inter-rater reliability equivalence or the notion of equivalence
- It is often a concern when different observers are using the same instrument to collect data at the same time.
- A coefficient can be calculated or other statistical or nonstatistical procedures can be used to see the correlation of values.
“Role of surveys in collecting data for nursing research: Questions answered”
Question 6. Describe the methods for assessing the reliability of measuring instruments.
Answer:
Methods of determining reliability
- The most common method of determining an examination’s reliability is the test-retest method.
Kuder Richardson Approaches:
- As explained previously, the same test is given to the same group on two separate occasions, usually a few days apart.
- The correlation between the two tests becomes the coefficient of reliability.
- Since rankings rather than raw scores are used to compute the correlation, the fact that most students usually do slightly better on the second test will not greatly affect the final results.
- The real problem with this method stems from students looking up answers after the first test.
- Some students may not look up any answers, while others may look up as many as they can remember.
- This would reflect intervening learning and would cause their scores to rise disproportionately. likely students talk about
- The same problem may occur when they test among themselves. We could expect that those who discuss the test would improve their scores, whereas those who do not discuss it will not improve or will improve only slightly.
- Another way to determine reliability is split-half correlation. Each student’s test is divided in half, usually with odd-numbered items making up one half and even-numbered items making up the other half. This produces two tests for each student that is then correlated with each other.
- A third method is to correlate some students‘ scores on equivalent forms or two tests that cover the same material although the specific questions are different.
- For example, the first test might contain the math problem 47 x 93, while the second contains 93 x 47.
- It is impossible to develop two tests with different questions that are exactly equal in difficulty, but we can make them fairly close.
- These two tests are then administered within a fairly short time period and, as before the results are correlated.
- The problem with this method is that it costs time and money, and it is hard to ensure that the two tests are equal but different.
“How do observational methods enhance research accuracy? FAQ explained”
Question 7. How the Researcher can increase reliability.
Answer:
- The various methods of determining reliability can never yield precise measures of a test’s unreliability.
- Correlation coefficients are only estimates or, more precisely, averages. For a teacher, the most important concern is how to increase reliability.
The following causes of unreliability should be avoided:
1. The sample of test items is skewed:
- That is, Some material only briefly mentioned in class is made an important part of the test, while other material extensively covered in class is only briefly touched on.
- If a test is not well balanced and does not test material in proportion to the emphasis it was given in class or in the text, reliability will be lowered.
- To remedy this situation, a table of specifications should be used to balance the test.
2. The wording of instructions and questions is ambiguous.
- This common problem may cause students to misinterpret the intent of a question or a portion of the test.
- Ambiguity may be reduced by revising test questions in accordance with feedback 3 from other teachers or based on the results of previous use, either in a practice test or with other classes.
3. Too many difficult items can lead students to do a great deal of guessing.
- Chance then plays an important role in the final scores. The more difficult a test is, the more its final scores are affected by chance.
- To solve this problem, the test should be made easier. The average difficulty level for a non-mastery test should be about 0.50.
4 . A short test usually has lower reliability.
- Probably the easiest way to increase a test’s reliability is by lengthening it.
- An average test that contains only 10 questions often has very little reliability, whereas a test of 70 questions of equal quality is likely to have greater reliability.
- The Larger the sample, all other things being equal, the more accurate the assessment of student’s level of achievement usually is.
“Early warning signs of gaps in understanding research tools: Common questions”
- Restrictive time limits can force hasty reading and responding, which affect students’ final scores.
- Students should generally be given plenty of time to finish a test. This ensures that they answer thoughtfully and minimizes quick guesses.
Question 8. Describe the pilot study in terms of its definition and importance.
Answer:
Pilot study in terms of Meaning:
- It is a small preliminary investigation of the same general character as the major study which is designed to acquaint the researcher with problems that can be corrected in proportion to the larger research project or is done to provide the researcher with an opportunity to try out the procedures for collecting data.
- The pilot study is a miniature trial run of the methodology planned for the major project.
- It is a time for detecting errors and flaws being made in the instrument for gathering data. Then when the actual study is carried out the researcher can profit from the mistakes made in the pilot study.
A pilot study in terms of Definition:
- According to Julie Stachowiak, A pilot study is a smaller version of a larger study that is conducted to prepare for that study.
- According to Short and Pigeon, Pilot studies are small-> scale rehearsals of larger data collections.
- According to Gordon Marshall, A Pilot study is any small-scale test of a research instrument (such as a questionnaire experiment or interview schedule), run in advance of the main fieldwork and used to test the utility of the research design.
“Success rate of interventions using modern research tools: FAQ”
A pilot study in terms of Importance:
- It tells us about the completeness, accuracy, and convenience of the sampling frame from which it is proposed to select the sample.
- It unfolds the variability within the population to be surveyed. It is important for determining the sample size.
- It helps in bringing out the inadequacies of the draft questionnaire.
- Throws light on several difficulties in the study.
- Shows the effectiveness of the training of the personnel or collecting data.
- Allays the interviewer’s fear of overtly sensitive questions and builds their self-confidence.
- Tests the interviewer’s stamina to work under conditions of personal discomfort, stress, and fatigue.
- Tests the efficiency of the survey organization in the field.
- Helps in identifying the needs for different kinds of equipment, and vehicles necessary during the project.
- Provides data for making estimates of time and costs for completing various phases of the project and shows ways to effect savings.
- The scale of the pilot study will depend on the availability of resources like time, money, and personnel.
- Provides for initial analysis of the adequacy of the questionnaire and the training instructions and supervision under field conditions.
- Aids to identify parts of the instrument package that are difficult for pretest subjects.
- Helps to identify objectionable or offensive questions.
- Assesses the sequencing of an instrument to be sensible.
- Determines the need for training of data collection staff.
- Determines whether the measurement yields data with sufficient variability.
“Asymptomatic vs symptomatic effects of ignoring proper research tools: Q&A”
Question 9. Define validity and types of validity.
Answer:
- The validity of an instrument refers to the degree to which an instrument measures what it is supposed to be measuring.
- For example, a temperature-measuring instrument is supposed to measure only the temperature; it cannot be considered a valid instrument if it measures an attribute other than temperature.
- Similarly, if a researcher developed a tool to measure the pain, and if it also includes the items to measure anxiety, it cannot be considered a valid tool.
- Therefore, a valid tool should only measure what it is supposed to be measuring.
Validity Definitions:
- According to Treece and Treece, ‘Validity refers to an instrument or test actually testing what it suppose to be testing’.
- According to Polit and Hungler, ‘Validity refers to the degree to which an instrument measures what it is supposed to measure’.
- According to the American Psychological Foundation, ‘Validity is the appropriateness, meaning, fullness, and usefulness of the interference made from the scoring of the instrument’. Validity is the appropriateness, completeness, and usefulness of an attribute-measuring research instrument.
“Why are research tools often misunderstood in practice? Questions answered”
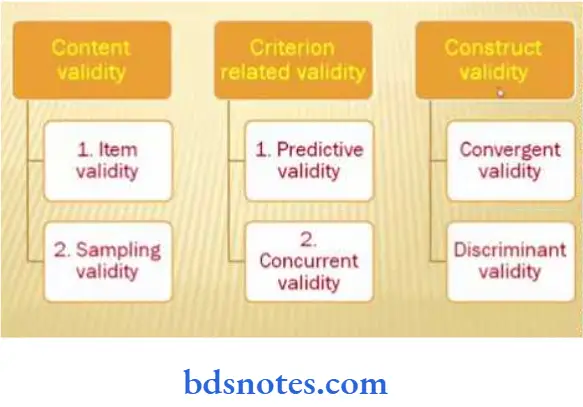
Types of Validity
Basically, validity is classified into the following four categories:
Face validity:
- Face validity involves an overall look of an instrument regarding its appropriateness to measure a particular attribute or phenomenon.
- Though face validity is not considered a very important and essential type of validity for an instrument.
- However, it may be taken into consideration while assessing other aspects of the validity of a research instrument. In simple words, this aspect of validity refers to the face value or the outlook of an instrument.
- For example, a Likert scale is designed to measure the attitude of the nurses towards the patients admitted with HIV/AIDS; a researcher may judge the face value of this instrument by its appearance, that is it looks good or not; but it provides no guarantee about the appropriateness and completeness of a research instrument with regards to its content, construct, and measurement score.
Content validity:
- It is concerned with the scope of coverage of the content area to be measured.
- More often it is applied in tests of knowledge measurement. It is mostly used in measuring complex psychological tests of a person.
- It is a case of expert judgment about the content area included in the research instrument to measure a particular phenomenon.
- Judgment of the content viability may be subjective and is based on previous researcher’s and experts’ opinions about the adequacy, appropriateness, and completeness of the content of the instrument.
- Generally, this viability is ensured through the judgments of experts about the content.
“Most common complications of poorly understood research methods: FAQs”
“Can targeted interventions improve outcomes using research tools? FAQs provided”
Criterion validity: This type of validity is a relationship between measurements of the instrument with some other external criteria.
- For example, a tool was developed to measure the professionalism among nurses; to assess the criterion validity nurses were separately asked about the number of research papers they published and the number of professional conferences they have attended.
- Later a correlation coefficient is calculated to assess the criterion validity.
- This tool is considered strong with criterion validity if a positive correlation exists between a score of the tool measuring professionalism and the number of research articles published and professional conferences attended by the nurses.
- The instrument is valid if its measurements strongly respond to the score of some other valid criteria.
- The problem with criterion-related validity is finding a reliable and valid external criterion.
- Mostly we are to rely on a less-than-perfect criterion because the rating found by empirical and supervisory methods may be computed mathematically,
- which can correlate the score of the instrument with the scores of the criterion variable. Here the range of coefficient &62;70 is desirable.
- Criterion-related validity may be differentiated by predictive and concurrent validity.
Predictive validity: It is the degree of forecasting judgment; for example, some personality tests on the academic futures of students can be predictive of behavior patterns.
- It is the differentiation between performances on some future criterion and instruments’ ability. An instrument may have predictive validity when its score significantly correlates with some future criteria.
“Difference between qualitative and quantitative research tools: Q&A explained”
Concurrent validity: It is the degree of the measures at present. It relates to the present specific behavior and characteristics; hence the difference between predictive and concurrent validity refers to the timing pattern of obtaining measurements of a criterion.
Construct validity:
- A construct is founded in this type of validity, such as a nurse may have designed an instrument to measure the concept of pain in amputated patients.
- The pain pattern may be due to anxiety; hence the results may be misleading. Construct validity is a key criterion for assessing the quality of a study, and construct validity has most often been addressed in terms of measurement issues.
- The key construct validity questions with regard to measurements are: What is this instrument really measuring? Does it adequately measure the abstract concept of interest?
- Construct validity gives more importance to testing relationships predicted on theoretical measurements.
- The researcher can make predictions in relation to another such types of constructs. One method of construct validation is known group technique.
Leave a Reply